Hello all 👋, In this blog I have tried to cover everything related to Standardization, Normalization & Feature Scaling along with the Code Sample & Examples, but before starting this make sure you know Python Programming Language along with that you are clear with the basic Data Science Concepts.
So, without any further thoughts let’s start the learning.
Feature Scaling?
Feature Scaling is an essential technique in the field of Data Scienceg that is used to standardize the Features present in our Dataset within a fixed range. This technique is used to bring values in different units into a single unit. This task is performed during data pre-processing phase. If the feature scaling is not done then the machine learning algorithms does not gives the expected results.
Let’s take an example in order to understand this concept. If you are working on some dataset in which few features are in meters and few are in kilometers. If the feature scaling technique is not applied then it can consider value 1000 meters is greater than 2 kilometers.
So now as we know what is feature scaling, let’s discuss how to use feature scaling and various techniques to perform Feature Scaling.
Below are the most used techniques that are used for feature scaling.
- Absolute Maximum Scaling
- Min-Max Scaling
- Normalization
- Standardization
- Robust Scaling
From the above mentioned techniques, we will be discussing 2 of them i.e Normalization and Standardization.
What is Normalization?
Normalization is a scaling technique in which values are shifted and rescaled in order to bring them within the range of 0 & 1. Normalization is also called as Min-Max Scaling.
Here is the formula of Normalization
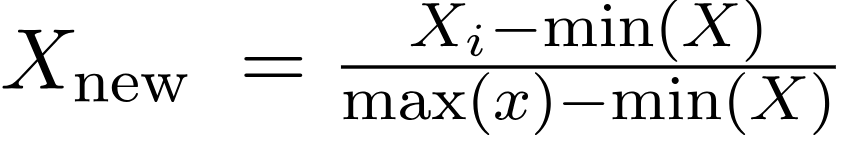
Here max(x) and min(x) are the maximum and minimum values of the features respectively.
◾ When the value of X(i) is minimum value in the column, then X(new) wlll be 0.
◾ When the value of X(i) is maximum value in the column, then X(new) wlll be 1.
◾ When the value of X(i) is between minimmum and maximum values in the column, then X(new) wlll be between 0 & 1.
So with the help of this formula, we have scaled our feature between 0 and 1.
Purpose
The goal of normalization is to change the values of numeric columns in the dataset to a common scale, without distorting differences in the ranges of values. For machine learning, every dataset does not require normalization. It is required only when features have different ranges.
What is Standardization?
Standardization is scaling technique where the values are centered around the mean with a unit standard deviation. This means that the mean of the attribute becomes zero and the resultant distribution has a unit standard deviation.
Here is the formula of Standardization
Here X(mean) and standard deviation is the mean and standard deviation of the feature values respectively.
Here the values are not restricted within a given range unlike normalization.
Purpose
Data standardization is the process of bringing data into a uniform format that allows analysts and others to research, analyze, and utilize the data. In statistics, standardization refers to the process of putting different variables on the same scale in order to compare scores between different types of variables.
So the biggest question now is that what should we use Normaliation or Standardization🤔
Standardization vs Normalization
Standardization can be used if the values of our feature follow a Gaussian distribution. However, this is not always always true.
While, Normalization can be used if a values of our feature does not follow a Gaussian distribution. It can be used with the algorithms that does not requires data to be in distribution like K-Nearest and Neural Networks.
Normalization and Standardization using Sklearn library
Brief about Feature Scaling and it’s Scaling techniques
Feature scaling is a scaling technique that is used in order to standardize our feature values within a fixed range and it is an essential technique in order to improve the efficiency of our machine learning algorithms and hence the resulting output.
There are various feature scaling techniques but in this tutorial we will be implementing Standardization and Normalization Scaling techniques only.
Normalization is a scaling technique that is used to bring feature values within a range of 0 and 1 given that features values does not follows a gaussian distribution.
Unlike normalization, Standardization is scaling technique where the values are centered around the mean with a unit standard deviation given that features values follows a gaussian distribution.
So, without any further do let’s start the practical demo and before starting this demo make sure you download the standardizaton_and_normalization.csv dataset from DS resources.
# Importing Libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Sklearn library
from sklearn import preprocessing
# Importing Data
data_set = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/Data_for_Missing_Values.csv')
data_set.head()
# Output
Country Age Salary Purchased
0 France 44 72000 No
1 Spain 27 48000 Yes
2 Germany 30 54000 No
3 Spain 38 61000 No
4 Germany 40 1000 Yes
# Slicing features age and salary to handle values with varying magnitude
x = data_set.iloc[:, 1:3].values
print ("\nOriginal data values : \n", x)
# Output
Original data values :
[[ 44 72000]
[ 27 48000]
[ 30 54000]
[ 38 61000]
[ 40 1000]
[ 35 58000]
[ 78 52000]
[ 48 79000]
[ 50 83000]
[ 37 67000]]
# Applying Normalization
normalization = preprocessing.MinMaxScaler(feature_range =(0, 1))
# After Normalization
after_normalization = normalization.fit_transform(x)
print ("\nAfter Normalization : \n", after_normalization)
After Normalization :
[[0.33333333 0.86585366]
[0. 0.57317073]
[0.05882353 0.64634146]
[0.21568627 0.73170732]
[0.25490196 0. ]
[0.15686275 0.69512195]
[1. 0.62195122]
[0.41176471 0.95121951]
[0.45098039 1. ]
[0.19607843 0.80487805]]
# Applying Standardization
Standardization = preprocessing.StandardScaler()
# After Standardization
after_Standardization = Standardization.fit_transform(x)
print ("\nAfter Standardization : \n", after_Standardization)
# Output
After Standardization :
[[ 0.09536935 0.66527061]
[-1.15176827 -0.43586695]
[-0.93168516 -0.16058256]
[-0.34479687 0.16058256]
[-0.1980748 -2.59226136]
[-0.56487998 0.02294037]
[ 2.58964459 -0.25234403]
[ 0.38881349 0.98643574]
[ 0.53553557 1.16995867]
[-0.41815791 0.43586695]]I hope from this example you have understood how to implement standardization and normalization using sklearn library and how it impacts the final outcomes in real world project scenario.
Overall Summary
So, now we know Feature scaling is a scaling technique that is used in order to standardize our feature value within a fixed range and it is an essential technique in order to improve the efficiency of our machine learning algorithms and hence the resulting output also we learnt normalization is a scaling technique that is used to bring feature values within a range of 0 and 1 given that features values does not follows a gaussian distribution, while Standardization is scaling technique where the values are centered around the mean with a unit standard deviation given that features values follows a gaussian distribution.
Conclusion
So, From this tutorial we have understood what is feature scaling and it’s various scaling techniques. Also how important is the role of feature scaling in improving the efficiency of machine learning algorithms also we learnt how and when to use Standardization and Normalization in real world projects. I hope you enjoyed this tutorial and it may have helped you in learning something new. Thank you for reading, have a nice day 😊

