
In the rapidly evolving landscape of web development, where the deployment of static websites on AWS is the norm, businesses are increasingly choosing Amazon S3 for hosting and global distribution through CloudFront.
This powerful combination ensures efficient content delivery across the globe, with CloudFront caching website content at edge locations for subsequent requests from the same region.
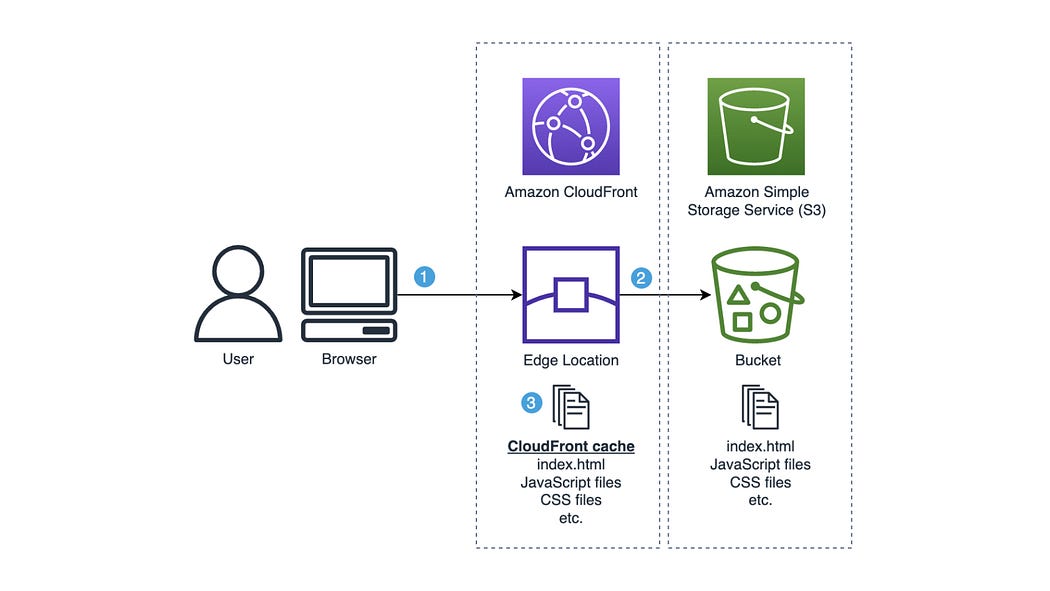
However, the challenge arises during new deployments, bug fixes, or critical updates when it becomes essential to clear the edge location cache and force CloudFront to deliver the latest and most updated content from the S3 bucket.
Manually invalidating the cache from the CloudFront distribution is an option, as outlined here. But what if there was a way to automate this cache invalidation process? Is there any possible solution for that?
The answer to this is “yes.” We can automate the cache invalidation using the Lambda function, a serverless offering by AWS. Note that this will add an extra penny to your cloud cost.
In this blog, we will be discussing two ways of achieving our goal.
- Invalidate the cache by triggering a lambda using S3 event triggers.
- Invalidate the cache by triggering a lambda using CodePipeline.
Prerequisites
Now that you are ready with the requirements, let’s directly jump in and look into both approaches.
Approach 1: Invalidate the cache by triggering a lambda using S3 event triggers
Step 1: Create a lambda function
Select Python as your runtime environment and a new execution role for your lambda.
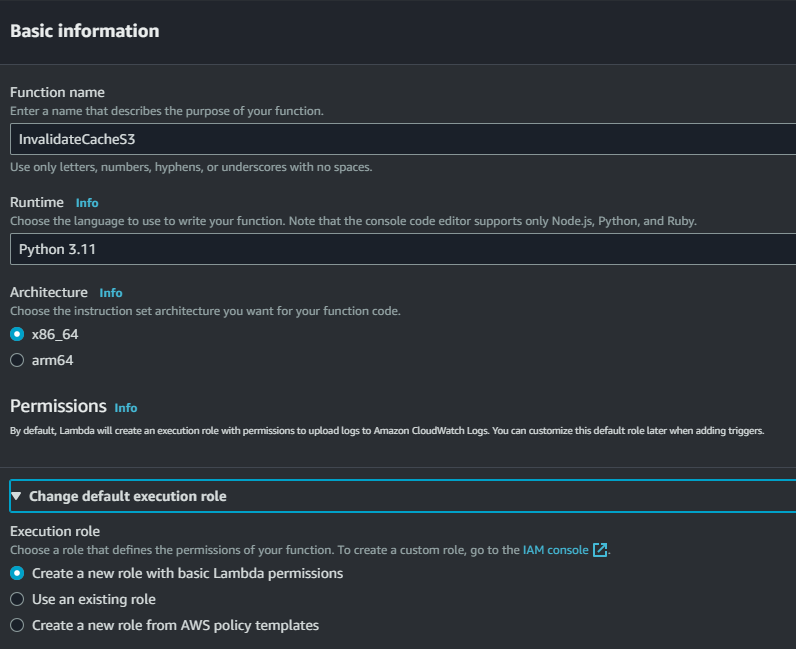
Use the below lambda code and replace it with your distribution ID and object path to be invalidated.
import json
import boto3
cloud_front = boto3.client("cloudfront")
def lambda_handler(event, context):
# Extract information from S3 event
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# Specify the CloudFront distribution ID
distribution_id = "your_cloudfront_distribution_id"
# Specify the object path to be invalidated (e.g., '/*' to invalidate all)
object_paths = ["/*"]
try:
# Create CloudFront invalidation
cloud_front.create_invalidation(
DistributionId=distribution_id,
InvalidationBatch={
'Paths': {
'Quantity': len(object_paths),
'Items': object_paths,
},
'CallerReference': str(hash(key)), # You can use a different reference based on your needs
}
)
except Exception as e:
print(f"Error: {e}")
raise eStep 2: Assign required permissions
Go to your lambda IAM role and attach an inline policy for lambda to invalidate cache. Replace ACCOUNT_ID and DISTRIBUTION_ID with your values.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "cloudfront:CreateInvalidation",
"Resource": "arn:aws:cloudfront::ACCOUNT_ID:distribution/DISTRIBUTION_ID"
}
]
}Step 3: Configure S3 event trigger
Navigate to your S3 bucket > Properties and create event notifications.
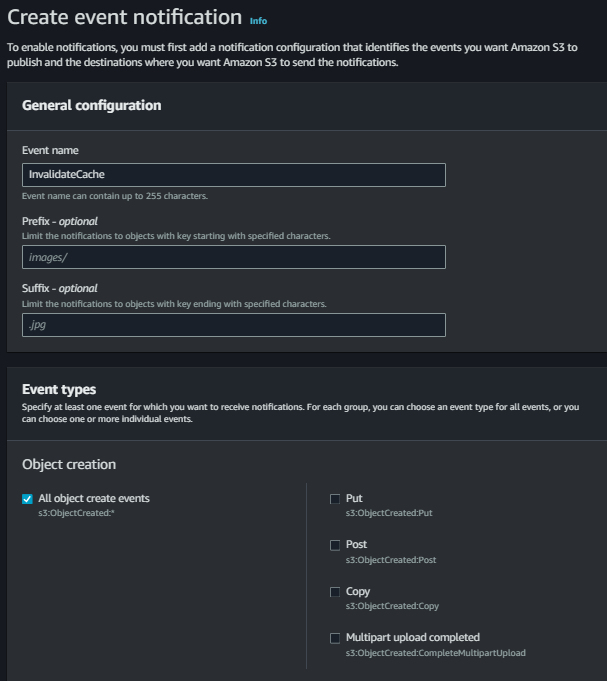
Select your lambda function as the destination and click save.
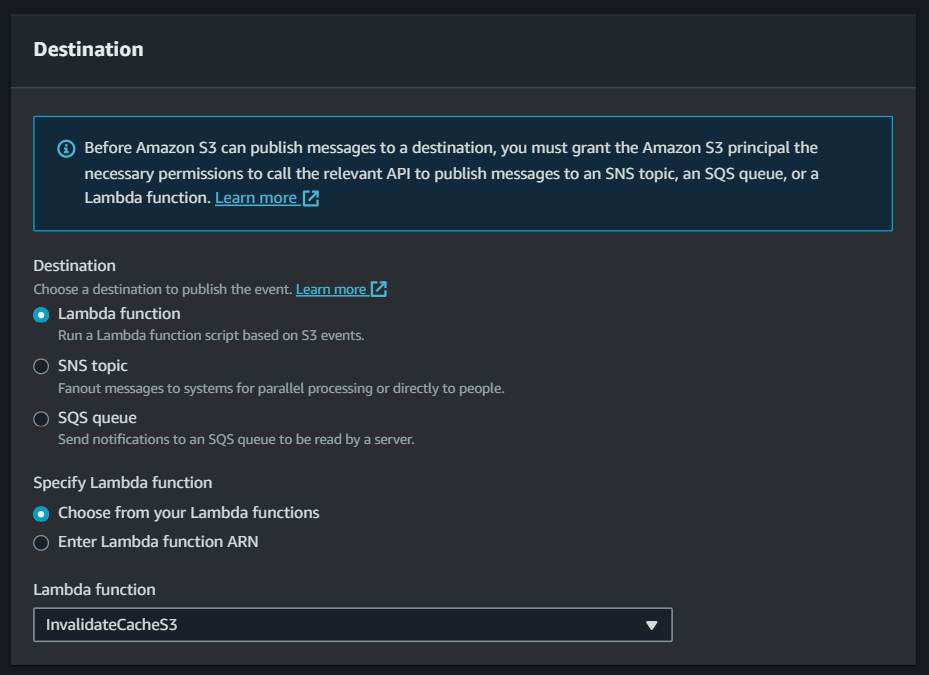
Done! Our setup is done, and now it’s time to test the functionality.
Step 4: Test the triggers.
Go to your S3 bucket and upload a new object.

Wollah Habibi 😍 we can see that in your distribution, new invalidation is created by our lambda function🎉

But wait a minute! For multiple file uploads at once, my lambda function is creating multiple invalidations, which is of no use. In fact, it is adding up a few extra pennies due to lambda invocation on every object upload. 😭

No need to worry! We have a solution for that too. Simply go to your S3 bucket properties, navigate to event notifications, and edit the event. Specify a prefix name such that when it changes, the Lambda function will be triggered.
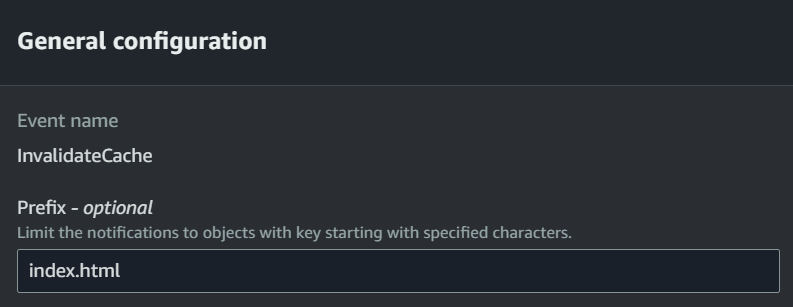
Everything is now complete in our 1st approach, and you can now finally celebrate 🍾.

Approach 2: Invalidate the cache by triggering a lambda using CodePipeline.
In this approach, the steps are pretty similar, but instead of S3 event notifications, our lambda function will be triggered by CodePipeline itself.
Step 1: Create Lambda function
Give a relevant name, select Python as a runtime environment, and select Create a new role.
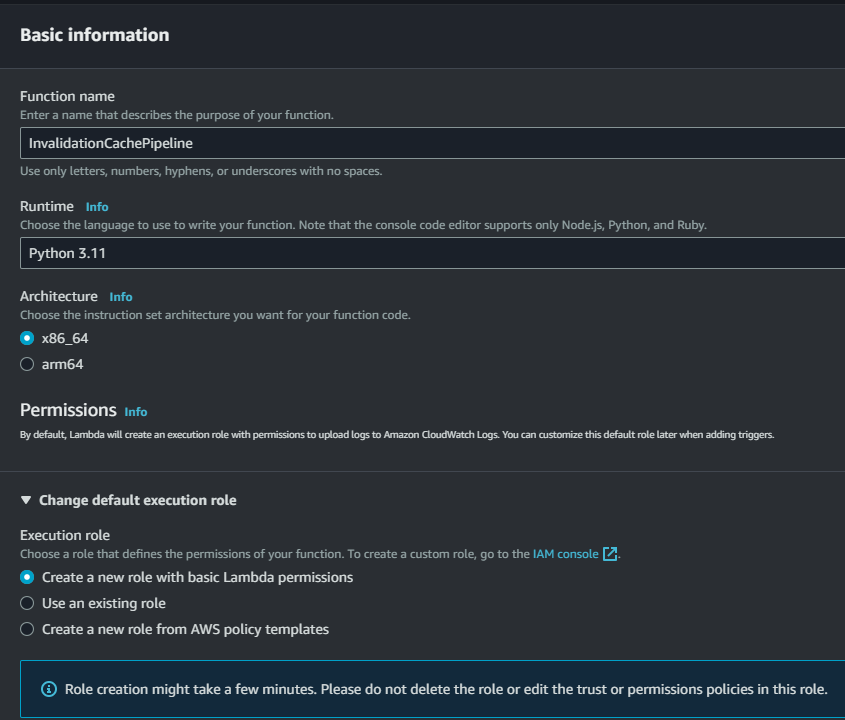
Paste the below code in your lambda function and deploy it. There is no need to change anything in the code.
import json
import boto3
code_pipeline = boto3.client("codepipeline")
cloud_front = boto3.client("cloudfront")
def lambda_handler(event, context):
job_id = event["CodePipeline.job"]["id"]
try:
user_params = json.loads(
event["CodePipeline.job"]
["data"]
["actionConfiguration"]
["configuration"]
["UserParameters"]
)
cloud_front.create_invalidation(
DistributionId=user_params["distributionId"],
InvalidationBatch={
"Paths": {
"Quantity": len(user_params["objectPaths"]),
"Items": user_params["objectPaths"],
},
"CallerReference": event["CodePipeline.job"]["id"],
},
)
except Exception as e:
code_pipeline.put_job_failure_result(
jobId=job_id,
failureDetails={
"type": "JobFailed",
"message": str(e),
},
)
else:
code_pipeline.put_job_success_result(
jobId=job_id,
)Step 2: Assign required permissions
Go to your lambda IAM role and attach an inline policy for lambda to invalidate cache. Replace ACCOUNT_ID and DISTRIBUTION_ID with your values.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"cloudfront:CreateInvalidation"
],
"Resource": [
"arn:aws:logs:us-east-1:ACCOUNT_ID:*",
"arn:aws:cloudfront::ACCOUNT_ID:distribution/DISTRIBUTION_ID"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"codepipeline:PutJobFailureResult",
"codepipeline:PutJobSuccessResult"
],
"Resource": "*"
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:lambda:us-east-1:ACCOUNT_ID:function:InvalidationCachePipeline:*"
}
]
}Step 3: Configure CodePipeline
In order to automate the cache invalidation process, we will be adding a new stage to our code pipeline. Navigate to your frontend pipeline and click on Edit.
Click on “Add stage” to add a new stage after deploying content to Amazon S3.

Name the stage “Cache-Invalidate” and add an action group.
- Specify action name of your choice
- Action Provider: AWS Lambda
- Region: Your region
- Input Artifacts: Select buildartifact
- Function Name: Select your function
- User Parameters: Specify your distribution ID and object path to be invalidated.
{"distributionId": "1234567890","objectPaths":["/*"]}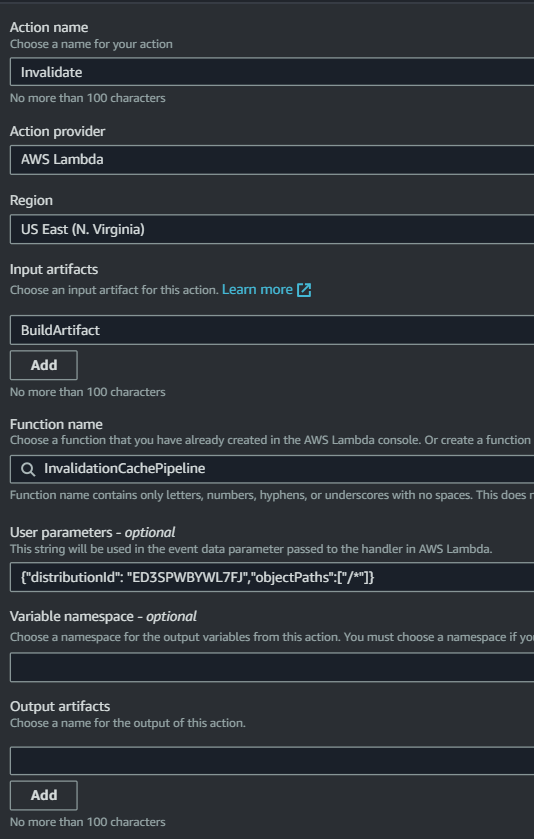
Click done, and save your pipeline. Now, it’s time to test your pipeline
Step 4: Test the Pipeline
Make a change in your source repo or release a change manually to test the entire execution.
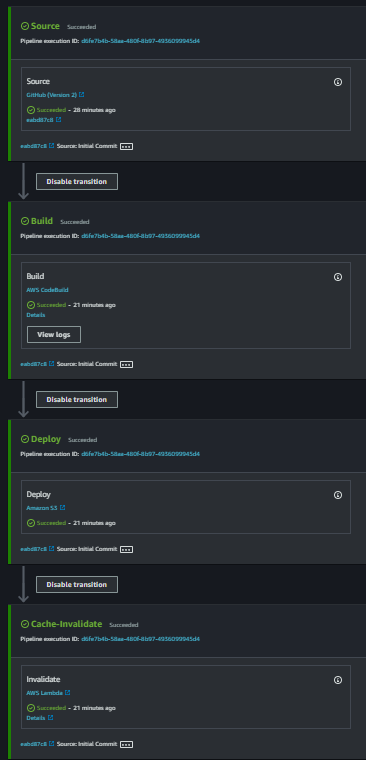
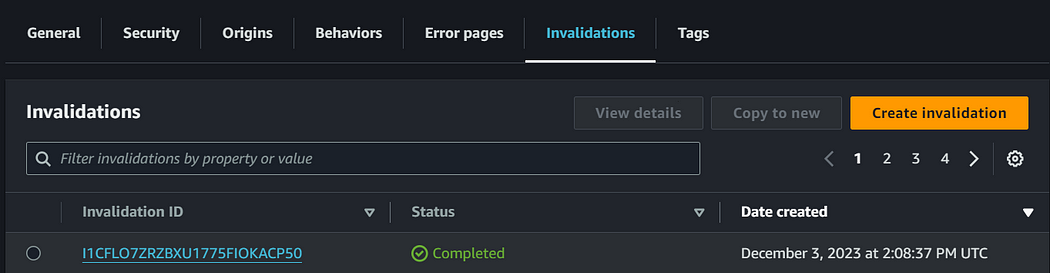
Hurray😍 our workflow is working as expected and our lambda function created new invalidation for our cloudfront distribution.

NOTE: In case you are facing any issues, make sure you have used the provided code and permissions policy. Still, if you face any errors, you can reach out to me via LinkedIn.
Conclusion
These two approaches provide automation for cache invalidation, ensuring that your CloudFront distribution serves the latest content after deployments, bug fixes, or updates. The guide covers the setup, configuration, and testing of both methods, offering flexibility based on your specific deployment workflows.
I hope this guide helped you understand both the automation strategies to invalidate your cloudfront distribution cache, and now you are ready to apply these strategies to your projects.
If you found this post helpful, give it a 👏 and follow for more useful blogs. Thanks, and have a great day!

